Tutorial - Part #6 - Quality Assurance¶
This final section of the turorial are not necesary for write a Pipeline. Here we try to elavorate some concepts and tools to make you confident about your data reduction. So here you gonna find the most unique feature of all pipelene frameworks: An integrated Quality Assurance (QA) for make thrustworty pipelines.
Some words about QA¶
In “Total Quality Control” (Feigenbaum, 1983) Feigenbaum defines software quality as
“Quality is a customer determination, not an engineer’s determination, not a marketing determination, nor a general management determination. It is based on the customer’s actual experience with the product or service, measured against his or her requirements – stated or unstated, conscious or merely sensed, technically operational or entirely subjective – and always representing a moving target in a competitive market”
In our context, a customer is not a single person but a role that our scientific requirements define, and the engineers are responsible for the design and development of a pipeline able to satisfy the functionality defined in those requirements. Measuring the quality of software is a task that involves the extraction of qualitative and quantitative metrics. One of the most common ways to measure Software Quality is Code Coverage (CC). To understand CC is necessary to define first the idea behind unit-testing. The unit-test objective is to isolate each part of the program and show that the individual parts are correct Jazayeri (2007). Following this, the CC is the ratio of code being executed by the tests –usually expressed as a percentage– (Miller and Maloney, 1963). Another metric in which we are interested, is the maintainability of the software. This may seem like a subjective parameter, but it can be measured using a standardization of code style; putting the number of style deviations as a tracer of code maintainability.
What is QA for Corral¶
As we said in the last paragraph, QA is subjective measure. That is the reason why Corral offers to the pipeline’s author tools to deliver higher quality code. This tools can measure three quantities: - Unit-test results, measuring the expected functionality - Coverage, which stands for the amount of code being tested - Style, as a estimator of the mantainability
Corral offers three tools to generate a global status report that brings an idea about the pipeline’s quality, so it is possible to share it to the stackholders.
Summarizing, is a pipeline’s developer job to define: - Which are the minimum tests to check the pipeline’s functionality - Assume that this testing set the baseline of the pipeline’s quality - Assume the risks of deploying it’s own code
Note
Following the subjectivity idea, this tool is optional, our original design comes from knowing ahead the amount of trust we put on deploying new versions of a pipeline, having settled before the “baseline”
Unit-Testing¶
From Wikipedia:
Intuitively, one can view a unit as the smallest testable part of an application. In procedural programming, a unit could be an entire module, but it is more commonly an individual function or procedure. In object-oriented programming, a unit is often an entire interface, such as a class.
Because some classes may have references to other classes, testing a class can frequently spill over into testing another class. A common example of this is classes that depend on a database: in order to test the class, the tester often writes code that interacts with the database. This is a mistake, because a unit test should usually not go outside of its own class boundary, and especially should not cross such process/network boundaries because this can introduce unacceptable performance problems to the unit test-suite. Crossing such unit boundaries turns unit tests into integration tests, and when test cases fail, makes it less clear which component is causing the failure. Instead, the software developer should create an abstract interface around the database queries, and then implement that interface with their own mock object. By abstracting this necessary attachment from the code (temporarily reducing the net effective coupling), the independent unit can be more thoroughly tested than may have been previously achieved. This results in a higher-quality unit that is also more maintainable.
In Corral’s case, a sub-framework is offered, in which is proposed to test separatedly in one or many test, the loader, each step and each alert.
For instance if we would like to test if the subject StatisticsCreator
each new instance of a Statistics for each instance of Name.
Note
We call subject to each step, loader and alert being put up to testing
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 | from corral import qa
from . import models, steps
class StatisticsCreateAnyNameTest(qa.TestCase):
subject = steps.StatisticsCreator
def setup(self):
name = models.Name(name="foo")
self.save(name)
def validate(self):
self.assertStreamHas(
models.Name, models.Name.name=="foo")
self.assertStreamCount(1, models.Name)
name = self.session.query(models.Name).first()
self.assertStreamHas(
models.Statistics, models.Statistics.name_id==name.id)
self.assertStreamCount(1, models.Statistics)
|
Breaking the code into pieces we have:
- On line number 5 we declare the test case, by setting a descriptive name
and inhering from class
corral.qa.TestCase. - On line 7, we link to the desired subject.
- From lines 9 and 11 (
setup()method), we prepare and add to the data stream an instance ofNamewith any name, since we know from the stepStatisticCreatordefinition that this model is being selected for an statistic. - On
validate()method (from line 13) the data stream status after executingStatisticCreatoris checked:- First of all on 14 and 15 lines it is verified that a effectively
exists a
Nameinstance in the stream with “foo” name. - In 16 it is checked that only one instance of
Nameexists on the stream (recall that each unit-test is executed isolated from every other, so whatever we added insetup()or whatever is being created by the subject are the only entities allowed to exist on the stream) - In line 18 we extract this one instance of
Namefrom the stream - Finally on lines 20 - 22, we verify that
StatisticsCreatorhas created an instance ofStatisticslinked to theNameinstance recently recovered, and that there is not any other instance in the Stream.
- First of all on 14 and 15 lines it is verified that a effectively
exists a
This testing example verifies the correct functioning of a simple step.
Take into account that it is possible to create more than one test with each
subject, by making variations on setup(), allowing to test different
initialization parameters for subject and generalizing to each possible state.
Important
Take into account that a test is not only to check that the code works properly. In many cases it is key to check that the software fails just as it should.
For example if you code a Step that converts images, you probably want several tests taking into account the most common images, such as a properly formatted image, as well as an empty bytes string, or an image that cannot fit into memory.
Executing Tests¶
To run the previously descripted test the test command is used:
$ python in_corral.py test -vv
runTest (pipeline.tests.StatisticsCreateAnyNameTest) ... ok
----------------------------------------------------------------------
Ran 1 test in 0.441s
OK
The -vv parameter increases the amount of information being screen printed.
Now if we change the test, for instance the 16 line, and insert the following:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 | from corral import qa
from . import models, steps
class StatisticsCreateAnyNameTest(qa.TestCase):
subject = steps.StatisticsCreator
def setup(self):
name = models.Name(name="foo")
self.save(name)
def validate(self):
self.assertStreamHas(
models.Name, models.Name.name=="foo")
self.assertStreamCount(2, models.Name)
name = self.session.query(models.Name).first()
self.assertStreamHas(
models.Statistics, models.Statistics.name_id==name.id)
self.assertStreamCount(1, models.Statistics)
|
and execute test again, we should get the following:
$ python in_corral.py test -vv
runTest (pipeline.tests.StatisticsCreateAnyNameTest) ... FAIL
======================================================================
FAIL: runTest (pipeline.tests.StatisticsCreateAnyNameTest)
----------------------------------------------------------------------
Traceback (most recent call last):
File "corral/qa.py", line 171, in runTest
self.validate()
File "/irispl/tests.py", line 40, in validate
self.assertStreamCount(2, models.Name)
File "/corral/qa.py", line 251, in assertStreamCount
self.assertEquals(query.count(), expected)
AssertionError: 1 != 2
----------------------------------------------------------------------
Ran 1 test in 0.445s
FAILED (failures=1)
This is due there are not 2 instances of Name in the Stream at that time.
Note
The test command supports a enormous quantity of parameters
to activate or deactivate tests, depend its subject, or stopping the
execution at the first error. Please execute python in_corral test --help
to get every possible alternative
Mocks¶
In many situations it is compulsory to make use of certain Python functionalities (or another third party library), that exceeds subject’s test scope, or any other kind of penalization with its use.
For example if we have any defined variable on settings.py called
DATA_PATH which points where to store any processed file,
and our subject creates data on that place. If we use this without caution
our testing cases might get filled with trash files in our working directory.
Mock Objects might be
useful in such times. These come already integrated inside TestCase
from Corral, and their key advantage is that after getting out of the
test case they are automatically whiped out.
import tempfile
import shutil
class SomeTest(qa.TestCase):
subject = # some subject
def setup(self):
# create a temporary directory
self.data_path = tempfile.tempdir()
# change the settings.DATA_PATH and set it as our temporary directory
self.patch("corral.conf.settings.DATA_PATH", self.data_path)
def validate(self):
# here, everything that makes use of DATA_PATH is being mocked
def teardown(self):
# here, everything that makes use of DATA_PATH is being mocked
# clean the temporary file so we do not leave trash behind us
shutil.rmtree(self.data_path)
The teardown() method does not need to restore DATA_PATH
to its original value, we just use it (in that case) to set free
disk space being utilized only inside the test.
Note
Corral mocks implement a big portion of Python mocks functionality, mainly de python, principalmente:
patchpatch.objectpatch.dictpatch.multiple
For more information on how to use mocks pleas go to https://docs.python.org/3/library/unittest.mock.html
Corral Unit-Test Life cycle¶
Each unit-test is executed in isolation, to guarantee this Corral executes each of the following steps for EACH test case:
Every class which inherit from
corral.qa.TestCaseare collected intests.pymoduleFor each TestCase is being executed:
- A testing database to contain the Stream is created.
- Every model is created on the Stream.
- A
sessionis being created, to interact with the DB, and a test case is being assigned to it. - The
setup()method is executed for the current testing case. - Database changes are confirmed and
sessionis closed. - The
subjectis executed, and it comes with its ownsession. - A new
sessionis created, and a testing case is assigned to it. - The
validate()method is executed andsessioncloses. - A new
sessionis created and testing case is assigned. - The testing case’s
teardown()method is executed. This method is optional, and could be used for example to clean auxiliary files if needed. - The database is destroyed, and every mock is erased.
Results for each test are recovered.
Important
The fact of creating 4 different session to interact with the databases
is guaranting that every communication inside the testing case is through the stream,
and not through any other in-memory Python object.
Note
The default testing database is an in-memory SQLite ("sqlite:///:memory:"),
but this can be overriden by setting the TEST_CONNECTION variable in
the settings.py module
Code-Coverage¶
The unittest are a simple tool to check the correct functioning of the pipeline. To get an idea of how well are doing our tests we compute the Code-Coverage (CC), and is equal to the percentage of lines of code being executed in the tests.
Important
How important is Code-Coverage?
CC is of so important in quality, that has been included in:
- The guidelines by which avionics gear is certified by the Federal Aviation Administration is documented in DO-178B and DO-178C.
- is a requirement in part 6 of the automotive safety standard ISO 26262 Road Vehicles - Functional Safety.
Corral calculates CC as the ratio of lines executed in testing, with respect to the total number of code lines in the pipeline (also including tests).
Corral is capable of self calculating the CC in the quality report tool described below.
Code Style¶
The programming style (CS) is a set of rules or guidelines used when writing the source code for a computer program.
Python favours the legibility of code as a design idiosincracy, stablished on PEP20. The style guide which dictates beauty and legible code is presented on PEP8
CS it is often claimed that following a particular programming style will help programmers to read and understand source code conforming to the style, and help to avoid introducing errors.
In some ways CS is some kine of Maintainability
As in coverage CS is managed by Corral integrating the Flake 8 Tool and is informed inside the result of the reporting tool
Reporting¶
Corral is capable of generating a quality report over any pipeline with testing.
Corral inspects the code, documentation, and testing in order to infer a global view of the pipeline’s quality and architecture.
To get access to this information we could use three commands.
1. create-doc¶
This command generates a Markdown version of an automatic manual for the pipeline, about Models, Loader, Steps, Alerts, and command line interface utilities, using the docstrings from the code itself.
When using the -o parameter we can switch the output to a file.
In this case Corral will suggest render the information in 3 formats
(HTML, LaTeX y PDF) using Pandoc (you will need to have Pandoc installed).
Example:
$ python in_corral.py create-doc -o doc.md
Your documentaton file 'doc.md' was created.
To convert your documentation to more suitable formats we sugest Pandoc
(http://pandoc.org/). Example:
$ pandoc doc.md -o doc.html # HTML
$ pandoc doc.md -o doc.tex # LaTeX
$ pandoc doc.md -o doc.pdf # PDF via LaTeX
Output examples can be found at: https://github.com/toros-astro/corral/tree/master/docs/doc_output_examples
2. create-models-diagram¶
This creates a Class Diagram in Graphviz dot format.
When using the -o flag we can switch the output to a file.
In this case Corral will attempt to render the diagram in a PNG
using Graphviz_ (you must install this library first).
$ python in_corral.py create-models-diagram -o models.dot
Your graph file 'models.dot' was created.
Render graph by graphviz:
$ dot -Tpng models.dot > models.png
More Help: http://www.graphviz.org/
Examples of output diagrams in dot and PNG can be found at: https://github.com/toros-astro/corral/tree/master/docs/models_output_examples
3. qareport¶
Runs every test and Code Coverage evaluation, and uses this to create a Markdown document detailing the particular results of each testing stage, and finally calculates the QAI index outcome.
When using the -o parameter we can switch the output to a file.
In this case Corral will suggest render the information in 3 formats
(HTML, LaTeX y PDF) using Pandoc (you will need to have Pandoc installed).
$ python in_corral.py qareport -o report.md
[INFO] Running Test, Coverage and Style Check. Please Wait...
Your documentaton file 'report.md' was created.
To convert your documentation to more suitable formats we sugest Pandoc (http://pandoc.org/). Example:
$ pandoc report.md -o report.html # HTML
$ pandoc report.md -o report.tex # LaTeX
$ pandoc report.md -o report.pdf # PDF via LaTeX
Examples of reporting output available at: https://github.com/toros-astro/corral/tree/master/docs/qareport_output_examples
Notes about QAI (Quality Assurance Index)¶
We recognize the need of a value to quantify the pipeline software quality. For example, using different estimators for the stability and maintainability of the code, we arrived to the following Quality Index includes in the QA Report:
The number of test passes and failures are the unit-testing results, that provide a reproducible and upda-table manner to decide whether your code is working as expected or not. The TP factor is a critical feature of the index, since it is discrete, and if a single unit test fails it sets the QAI to zero, displaying that if your own tests fail then no result is guaranteed to be reproducible.
The \(\frac{T}{PN}\) factor is a measure of how many of the different processing stages critical to the pipeline are being tested (a low value on this parameter should be interpreted as a need to write new tests for each pipeline stage).
The \(COV\) factor shows the percentage of code that is being executed in the sum of every unit test; this displays the “quality of the testing” (a low value should be interpreted as a need to write more extensive tests).
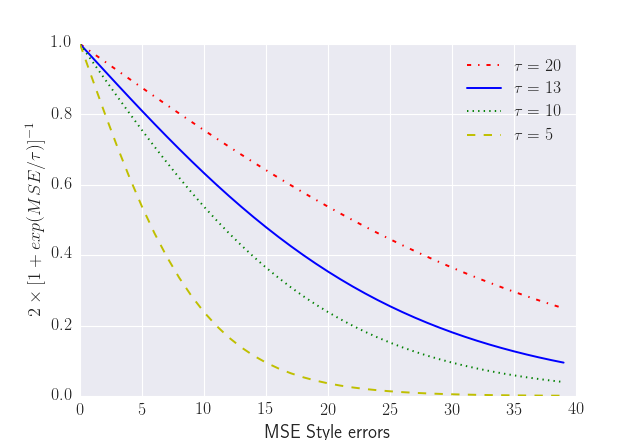
The last factor is the one involving the exponential of the \(\frac{MSE}{\tau}\) value. It comprises the information regarding style errors, attenuated by a default or a user-defined tolerance \(\tau\) times the number of files in the project \(PFN\) The factor $2$ is a normalization constant, so that \(QAI \in [0, 1]\).
Note
By default \(\tau = 13\) (the number of style errors on a single python script) is empirically determined from a random sample of more than 4000 python scripts.
You can change it by defining a variable on settings.py called
QAI_TAU and asigned some number to it.
As you can see in the graph the slope (penalization) of the QAI curve is lower when \(\tau\) is bigger.
Notes about QA Qualification¶
The QA Qualification (QAQ) is a quantitave scale based on QAI. Its a single symbol asigned to some range of a QAI to decide is your code aproves or not your expeted level of confidence. By default the top limits of the QAQ are the same system used by three different colleges in the United States:
Where
- If your \(QAI >= 0.00%`\) then the \(QAQ = F\)
- If your \(QAI >= 60.00%\) then the \(QAQ = D-\)
- If your \(QAI >= 63.00%\) then the \(QAQ = D\)
- If your \(QAI >= 67.00%\) then the \(QAQ = D+\)
- If your \(QAI >= 70.00%\) then the \(QAQ = C-\)
- If your \(QAI >= 73.00%\) then the \(QAQ = C\)
- If your \(QAI >= 77.00%\) then the \(QAQ = C+\)
- If your \(QAI >= 80.00%\) then the \(QAQ = B-\)
- If your \(QAI >= 83.00%\) then the \(QAQ = B\)
- If your \(QAI >= 87.00%\) then the \(QAQ = B+\)
- If your \(QAI >= 90.00%\) then the \(QAQ = A-\)
- If your \(QAI >= 93.00%\) then the \(QAQ = A\)
- If your \(QAI >= 95.00%\) then the \(QAQ = A+\)
This values are defined by a dictionary in the form
{
0: "F",
60: "D-",
63: "D",
67: "D+",
70: "C-",
73: "C",
77: "C+",
80: "B-",
83: "B",
87: "B+",
90: "A-",
93: "A",
95: "A+"
}
As you can see every key is the lower limit of the QAQ, you can change this
by adding the SCORE_CUALIFITACIONS variable to the settings.py of
your pipeline.
For example if you want to simple send a “fail” or “pass” message when your pipeline QAI are below or under \(60%\) you can add to your settings.py
SCORE_CUALIFICATIONS = {
0: "FAIL",
60: "PASS"
}